The Data Scientist’s Toolkit: Hive
By Kat Campise, Data Scientist, Ph.D.
While data scientists hail from many different disciplines, one of the most prominent characteristics shared by a majority is a curiosity that moves beyond merely “wondering” about a topic. Swift Google searches and a cursory examination of facts and figures isn’t sufficient for the data science mind. Data scientists are surgical about data as they parse through all of the noise using various, yet precise, tools within their operating environment. Big data requires industrial sized toolkits as organizations need to establish how to store, access, and manipulate the enormous data surge cascading in from a multitude of sources.








The social media and information technology giants might not have been the first to try to tackle the big data problem, but the likes of Facebook, Google, and Twitter (to name just a few) devised various technological infrastructure solutions that continue to be used in the data sense-making quest. The Hadoop system, with its multitude of functional components and layers, which includes Hive, has been implemented by thousands of enterprises across the U.S.: Netflix, Glassdoor, Slack, Intuit, Apple, Hulu, Target, and Amazon are several of the more prominent employers that advertise Hive — in particular — as a sought-after skill set for their data scientists, business intelligence engineers, and senior analysts.
What is Hive and What does it do?
As described in our Hadoop Guide, there is a substantial ecosystem attached to Hadoop and Hive is one piece of the larger puzzle. Initially created by Facebook, Hive is a data warehouse solution constructed as a layer on top of Hadoop’s Distributed File System (HDFS). In a distributed file system, there are chunks of data dispersed amongst separate data storage units; it may be helpful to view distributed storage as partitioned containers where data files wait for you to pull them into the data warehouse. Hive provides the centralized data warehouse component for summarizing, querying, and analyzing the data pulled from the HFDS. SQL is the most common language used for data management, and Hive has a SQL-like language (HiveQL) that provides the same SQL utility for Hadoop users.
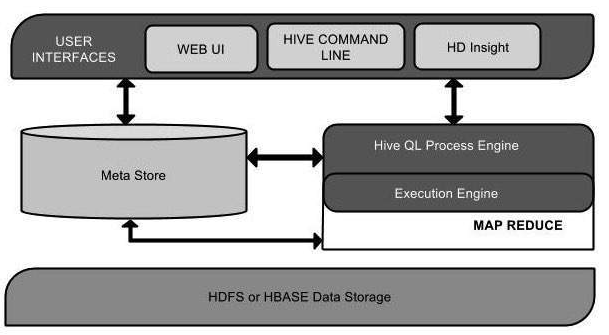
Image Source: Tutorialspoint
Why Learn Hive?
If your data science career goal is to work with any of the tech giants mentioned above, it’s highly likely (if not absolutely assured) that you will work with both Hadoop and Hive. The overall Hadoop market, of which Hive is an essential puzzle piece, has grown from a mere $8.48 billion in 2015 to $24.3 billion in 2018, and it’s projected that Hadoop and the big data market will exceed $90 billion by the year 2022. Suffice to say, the Hadoop software collection is here to stay for the foreseeable future, so it would be prudent for aspiring data scientists to learn and add to their ever-expanding toolkit.
At a more granular level, Hive simplifies working with huge datasets. Now, defining “huge dataset” is where things get tricky as there is no clearly delineated cut off point that is universally accepted. But, if you cannot process the data using a single computer, meaning it requires parallel processing distributed across several pieces of hardware, then it’s safe to assume you have a large dataset. Hive is scalable and has a short learning curve for those who know SQL. For those data scientists who don’t have a strong programming background, Hive is relatively easy to learn via hands-on experience.
Essential Background Knowledge
All data scientists should have some programming knowledge whether or not the enterprise they are working for uses Hadoop and Hive. Considering that there are several entry points for Hive (see the graphic above), and Hadoop is built on the Java programming language, knowledge of the following will provide you with a head start in quickly and accurately learning how to use Hive:
- Using the CLI (command line interface);
- Understanding the Hadoop ecosystem and how data is stored and processed;
- SQL knowledge is helpful for quick transfer of learning to Hive’s SQL-like language;
- Knowing the difference between structured, unstructured, and semi-structured data;
- Familiarity with Linux OS;
- A working knowledge of Python and Java;
- Prior work with large datasets including extraction, transformation, loading (ETL), cleaning, and analysis is helpful.
Resources for Learning Hive
Big data is big business, and there is no shortage of online learning opportunities for Hive. MOOCs and other tutorials are widely and freely available to all self-motivated learners. Some provide video instruction followed by hands-on practice with Hive, while others function as more of a guidebook or user documentation for digging deeper into the ins and outs of Hive architecture.
- Coursera: Big Data Analysis: Hive, Spark SQL, DataFrames, and GraphFrames offers learners a four-week crash course on both Hive and Spark. This course is part of a Big Data for Engineers specialization designed by Yandex. Learners may either audit the course for free or purchase the course to earn a certificate.
- Lynda: Analyzing Big Data with Hive is a short course — one hour and 53 minutes in length — that takes learners through Hive essentials. If you’re new to Lynda, you’ll be able to start on this course without cost. After the free 30 day trial, you have a choice of either a Basic Membership (currently $19.99 per month) or a Premium Membership ($24.99 monthly).
- Hortonworks: The Hortonworks “How to Process Data with Apache Hive” tutorial will take learners through a step by step learning path for creating tables and queries. The upside is that it’s entirely free for For those of you who prefer video tutorials, it is advisable to follow the Hortonworks guide to gain some basic background knowledge, and then either visit one of the other video intensive online learning providers listed in this article or perform a search on YouTube for recent video tutorials as a supplementary learning tool.
- Tutorialspoint: The Hive Tutorial offered by Tutorialspoint is akin to a textbook-type format where learners can self-navigate to their “how to” of interest. For the cost conscious learner, their tutorial is free to use.
- LinkedIn Learning: LinkedIn has joined the online learning realm and has an Analyzing Big Data with Hive As with Lynda (LinkedIn and Lynda are instructional design partners), you can sign up for 30 days and access the module for free. After 30 days the $19.99 or $24.99 per month charge will be applied.
Data science is a lifelong adventure in learning the newest tools and approaches to wrangling all things related to big data. As technological innovation moves forward, data scientists will also need to acquire additional skills and abilities throughout their career. Fortunately, for the time being, you can leverage that learning to command higher salaries as the need for data scientists isn’t abating any time soon.